It has been a while since my last post in series of machine learning for newbie. This time, we will discuss a bit on the loss functions. But what is the loss function, anyway?
0. Preliminary
Let’s get started with the problem of making prediction on new unseen data based on given training data. This problem includes both regression and classification as its specific cases. More specificially, we consider a predictive function $f: \mathcal{X} \rightarrow \mathcal{Y}$, with input (covariate, feature vector) $x \in \mathcal{X}$, and output (label) $y \in \mathcal{Y}$. For a given $x$, we try to predict its corresponding output as $f(x)$ such that $f(x)$ is as close to the true output as possible. It’s clear that we need some ways to measure how close (how good) our prediction is to the true value. That where a loss function comes in. In this post, unless stated otherwise, we consider a loss function $l: \mathcal{Y} \times \mathcal{Y} \rightarrow \mathcal{R}$ such that $l(f(x), y)$ tell you how close our prediction $f(x)$ to the true value $y$ in a quantitative manner. The problem of making prediction is simply equivalent to learning the predictive function f(x) which minimizes the expected risk:
(*)
where $\mathcal{F}$ is our model from which we select the predictive function, P(x,y) is the underlying joint distribution of input x and output y. We will talk about model selection and how to minimize the expected risk above, e.g. empirical risk minimization (ERM) in other posts. For now, let us focus on the problem of choosing the appropriate loss function. More specifically, different types of loss functions might lead to different solutions of the minimization problem above. In other words, the loss function should be carefully selected depending on specific problems, and our purposes. From now, we will take a tour over some common loss functions and their usage.
I. Loss Functions in Regression
For simplicity, we often consider $\mathcal{Y} = \mathbf{R}$ in regression setting.
1. Squared Loss:
.
This is one of the most natural loss function we might come up with at the first place. Under this loss function, our expected solution to the minimization problem (*) is: for a given input .
In other words, we will obtain the conditional mean as the solution of ordinary least squares regression with the squared loss function.
2. $\tau$-quantile loss:
$~~~~~~~~~~l(f(x),y) = (1-\tau)\mathrm{max}(f(x)-y,0) + \tau\mathrm{max}(y-f(x),0)$,
for some $\tau \in (0,1)$.
Under this loss function, our expected solution for (*) is: . In other words, we obtain the $\tau$-quantile point of the conditional probability $P(Y|X=x)$. Especially, when $\tau = 0.5$, $l(f(x), y) = |f(x)-y|$, and the solution is the median of the conditional probability $P(Y|X=x)$.
II. Loss functions in Classification
Here we only consider the binary classification problem where . However, the loss functions discussed here also generalize to the multiclass problems as well.
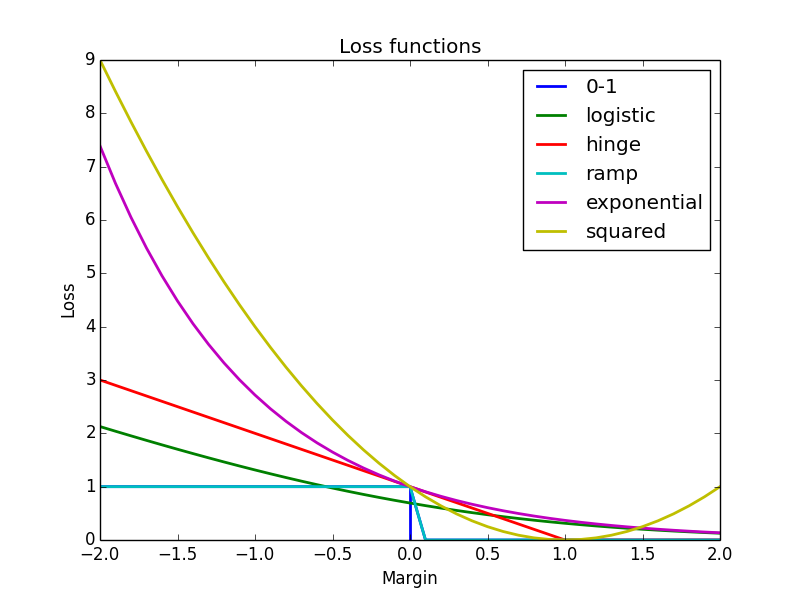
1. 0-1 loss:
In binary classification, our objective is to minimize the misclassfication error as
(**)
where , and $l(f(x), y) = \boldsymbol{1}[y \neq f(x)]$ is called 0-1 loss, such that:
The predictive function that minimizes the objective (**) above is called the optimal Bayes classifier:
Astute readers might notice that the discreteness of output domain ${+1, -1}$ makes our predictive function not quite comfortable to handle. So, let us consider a predictive function similar to regression case, i.e. $f: \mathcal{X} \rightarrow \mathbf{R}$, and just take the sign of this function to classify the input,
This further leads to the concept, called margin, defined as $m(x) = yf(x)$. Intuitively, a positive/negative margin means correct/wrong classification. Intuitively, the larger than 0 the margin is, the more confidence we have in our prediction. This idea is related to maximum margin classifier, where the popular Support Vector Machine (SVM) is an example.
Another problem is that while there is nothing wrong with the straightforward 0-1 loss, its non-convexity leads to difficultly in solving our optimization problem. In general, there are no guarantees about minimization with non-convex optimization functions. That’s why it is common practice in machine learning that people uses convex loss functions, whose convexities guarantees that we can find the (unique) minimum for our optimization problem, as a proxy for the 0-1 loss. See, e.g., Peter L. Bartlett, et al. Convexity, Clasification, and Risk Bounds for theoretical justification of using the convex surrogate losses. Now, let’s take a look at some common convex surrogate losses in classfication.
2. Convex surrogate losses
The convex surrogate losses are often defined as functions of the margin mentioned above. Intuitively, the surrogate loss should be a monotonically decreasing function, i.e., the larger the margin, the smaller the incurred loss shoud be.
* Logistic loss
.
This loss function is used in Logistic regression, which actually is a classification technique despite its name. From the probabilistical perspective of logistic regression, minimizing the logistic loss is equivalent to maximizing the conditional log-likelihood log P(Y|X).
* Hinge loss
.
This loss function is used in Support Vector Machine. Since it is unbounded as the margin is getting negatively smaller, this loss function may be sensitive to outlier in the data. Its bounded variant, called Ramp loss is proposed to be more robust against outlier.
.
* Exponential loss
.
This loss function is often used in Boosting algorithm, such as Adaboost. What Adaboost actually does is minimizing the exponential loss function with training data. Again, its sensitiveness to noise in data leads to many proposed robust boosting algorithms, e.g., Madaboost, Logitboost which use more robust loss functions.
.
Since a picture might worth a thousand words, let me conclude with an illustrative figure, including plots of loss functions we discussed in this long post. Until next time!