Many C++ beginners (e.g. me) enjoy pushing buttons to have their programs compiled and run smoothly (if no errors). We just take for granted some magic things happen behind the scene in our favorite IDE. Have you ever wondered how your text-based C++ source code was transformed into the final executable. In this post, we will look into the C++ compilation model, particularly the preprocessor. These things might help us gain more insight into our programs, our bugs, and understand source code written by other better.
1. C++ compilation model
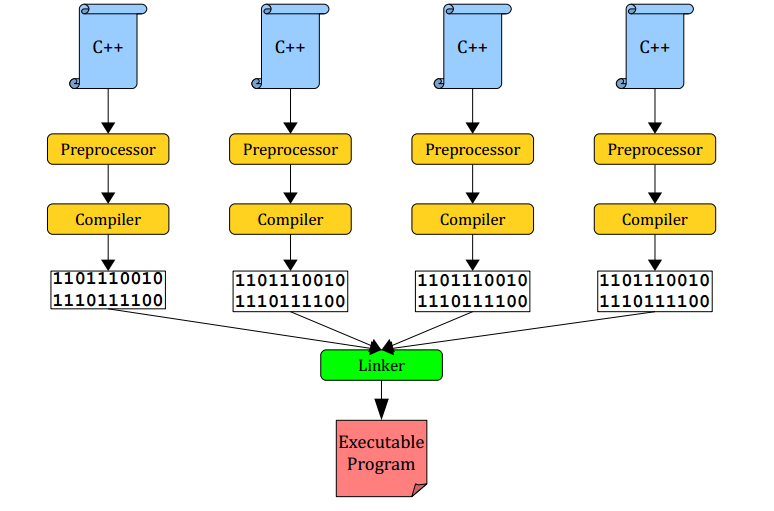
As you know, C++ is a compiled language, that means before a C++ program executes, we have a special program, called compiler to convert the C++ source code into machine code. Once the program is compiled, a computer can run the resulting executable for any number of times, even if the original source code is not available. The fairly complex compilation process can be broken down into 3 main steps:
-
Preprocessing: During this step, a special program, called the preprocessor scans over the C++ source code and applies transformations to it. For instance,
#includedirectives are resolved to make various libraries available, special tokens, e.g.__LINE__,#define-d constants and macros are replaced by their appropriate values. -
Compilation: The compiler read in the C++ source files, optimize, transform them into
object files. These object files are machine and compiler dependent, but usually contain machine code which executes the instructions written in C++ files, along with extra information. Thecompile error(CE) if any will be reported at this stage. Note that during the compilation step, each C++ source file is treated independently. -
Linking: A program, called
linkergather all the object files generated in compilation phase, and build the final executable that can be run and distributed. During this step, the linker might report some final errors.
Understanding the compilation model might help us quickly nail down sources of errors, demystify some otherwise cryptic error messages, and debug efficiently. The whole compilation process is illustrated in the figure below.
2. Preprocessor in detail
As mentioned above, the first big step in the compilation process is preprocessing, where a special program, called preprocessor reads in directives and modifies source code before giving it to the compiler for further transformation. While the preprocesor is powerful, it is difficult to use correctly and can lead to subtle and complex bugs. It has been controversial among programmers that whether preprocessor techniques should be used instead of alternative solutions which often clearer and safer. IMHO, everything has pros and cons, thus getting to know the tools, in this case preprocessor techniques before making any decision is more important than taking side without much understanding. Personally, I’ve found some preprocessor techniques quite useful.
2.1. #include directive
-
Basically, it tells the preprocessor to import library code into the program. More concretely,
#includedirective asks the preprocessor to locate a specified file and insert its contents in place of the directive itself. For instance, if you write#include <iostream>, during the preprocessing step, the preprocessor will look for the content ofiostream, then copy and paste it into your source file in place of the directive. -
What if you double types the same #include <header>? Does that cause the same code is copied and pasted twice. If so, this will causes compile errors. Thus, comes the “#include guarding” technique, which ensures that content of a header file is included only once. You might see something like:
#ifndef xxx_INCLUDED
#define xxx_INCLUDED
// something goes here
#endif
Basically, this ensures xxx header content is included only once. -
You might also wonder what is difference between
#include <xxx>and#include "xxx". In the former case, where the filename xxx is surrounded in angle brackets, the preprocessor will look into a compiler-specific directory containing C++ standard library files. In the latter case, when filename is surrounded in quotes, the preprocessor will look into the current directory for the xxx. And last but not least, keep in mind that#includeis a preprocessordirective, not a C++ statement, that means it must not end with a semicolon.
2.2. #define directive
-
One of the most commonly used and abused preprocessor directives. Basically it tells the preprocessor to look for specified phrases in the source code and replace them with appropriate values. The basic syntax is
#define SOMETHING REPLACEMENT. Let’s consider some examples.
Q1.#define MY 1
The line above means everytime the preprocessor see aMYin the source code, just replace it with 1 (as an int, not string).
Q2.#define MYvs#undef MY
Obviously, you can define a phrase without replacement part. In this case,MYwill be defined asnothingness. Note that it is different from#undef MY, by this you undefineMY. In the former case, you do defineMYasnothingness, but in the latter case,MYis undefined and any of its usage without redefining will lead to compile errors. -
Now, go to one of the most common and complex usage of
#define: macro definition. The syntax looks like this:
#define macroname(param_1,...,param_n) macro_body.
This is basically the same as using #define for constant definition. When the preprocessor encounters a call to a function namedmacroname, it will replacemacronamewith the text inmacro_body. However, unlike normal C++ functions, preprocessor macros do not have return values. Obviously, you can write a normal function which does exactly the same thing as a macro does. So, what is the point of using a macro? An answer might be using macro for routine code would save you a significant overhead of function calls, then be much more efficient in terms of performance than normal function, particularly in the old day when computer was not fast. What aboutinlinefunction? Inline function can help improve performance, butinlinekeyword does not force the function to be inlined. Instead it only suggests the compiler to inline the function if possible.
While preprocessing techniques are pretty powerful, at the same time they can lead to unexpected and subtle logic which different from programmer’s original intention. If you don’t believe, check out the code below and guess what happen behind the scene without using your compiler.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
This post has been too long, so some advanced preprocessor techniques, e.g. String manipulation, special preprocessor values, X Macro Trick will be deferred to a follow-up post in the near future. Stay tuned!